
IaC Principles
Infrastructure as Code is not a tool or a technology - it is a discipline and a philosophy. It means applying the same practices used to build reliable software (version control, testing, code review, automation) to the infrastructure that software runs on.
The shift from manually managed servers to code-defined infrastructure is one of the most consequential changes in how modern systems are built and operated.
From the Iron Age to the Cloud Age
Section titled “From the Iron Age to the Cloud Age”Traditional “Iron Age” infrastructure was static. Servers were physical machines, provisioned by hand, configured manually, and treated as long-lived, precious resources - the “pet” model. Changing them was risky. Replacing them was expensive.
Cloud-age infrastructure is dynamic. Resources are API-driven, provisioned in minutes, and designed to be disposable - the “cattle” model.
| Iron Age | Cloud Age |
|---|---|
| Physical servers, manual provisioning | API-driven, programmatic provisioning |
| Servers as pets - named, cherished, maintained | Servers as cattle - numbered, replaced on failure |
| Infrastructure changes are risky, infrequent | Infrastructure changes are routine, automated |
| Snowflake configurations (unique, fragile) | Reproducible, identical environments |
| Change management is a bottleneck | Change management is embedded in code review |
The Three Core Practices
Section titled “The Three Core Practices”IaC rests on three practices that every team must adopt before anything else:
1. Define Everything as Code
Section titled “1. Define Everything as Code”If it’s not in code, it doesn’t exist. This includes:
- Compute resources (VMs, GKE node pools, Cloud Run services)
- Networking (VPCs, subnets, firewall rules, load balancers)
- IAM (service accounts, bindings, organization policies)
- Storage (buckets, databases, Pub/Sub topics)
- Configuration (environment variables, feature flags)
Code also enables sharing and cascade improvements. Instead of every team manually researching and configuring complex components like a VPC or a Kubernetes cluster, one team writes a reproducible module and shares it across the organisation. When that module is improved - say, by adding security monitoring or a compliance control - the update cascades to every team using it, exactly like upgrading a shared software library. This is the compounding return of IaC that manual infrastructure management can never achieve.
2. Continually Test and Deliver All Work in Progress
Section titled “2. Continually Test and Deliver All Work in Progress”IaC that is only applied once a week is not continuous delivery - it’s batch infrastructure changes. IaC should be held to the same standard as application code: every commit triggers validation, every PR triggers a plan review, and merging to main triggers automated deployment.
3. Build Small, Simple Pieces That Can Change Independently
Section titled “3. Build Small, Simple Pieces That Can Change Independently”Monolithic infrastructure stacks - one giant Terraform configuration that manages everything - are the infrastructure equivalent of a monolithic application. When something changes, everything is at risk. Small, composable stacks with clear interfaces fail in isolation and change safely.
The Four Key Metrics (DORA for Infrastructure)
Section titled “The Four Key Metrics (DORA for Infrastructure)”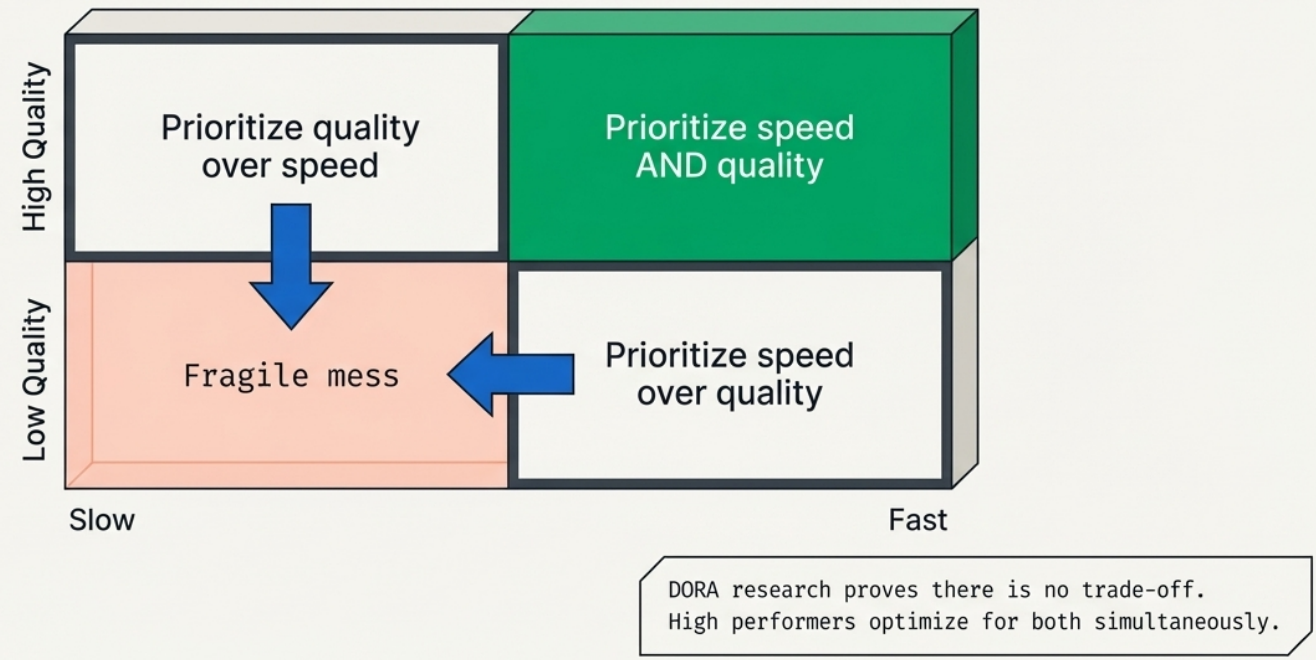
The same DORA metrics used to measure software delivery performance apply directly to infrastructure:
| Metric | Infrastructure meaning |
|---|---|
| Deployment frequency | How often infrastructure changes are applied to production |
| Lead time for changes | Time from an infrastructure change commit to it running in production |
| Change failure rate | Percentage of infrastructure changes that cause incidents |
| MTTR | How quickly infrastructure failures are recovered from |
Principles of Cloud Infrastructure
Section titled “Principles of Cloud Infrastructure”Beyond the three core practices, seven properties define well-designed cloud infrastructure.
1. Assume Systems Are Unreliable
Section titled “1. Assume Systems Are Unreliable”Cloud infrastructure operates at massive scale - thousands of devices where hardware failure is a mathematical certainty. Some providers intentionally use cheaper hardware, relying on automated replacement over prevention. As Werner Vogels puts it: “Everything fails all the time.”
Design for uninterrupted service even as underlying resources change, fail, or are replaced. Routine maintenance (patching, resizing, redistribution) happens constantly - taking systems offline means taking the business offline. This assumption is the foundation of chaos engineering: deliberately injecting failures under controlled conditions to test and improve system resilience.
2. Make Everything Reproducible
Section titled “2. Make Everything Reproducible”Any part of the system should be rebuildable from code without decision-making - configuration, software versions, and dependencies are strictly defined. This enables:
- Point-in-time restoration - rebuild the system exactly as it existed at a previous state
- Environment consistency - test environments perfectly mirror production
- High availability - replicate systems across regions
- Dynamic scaling - add instances on demand during high load
- Customer isolation - replicate entire systems for dedicated customer instances
Running systems generate dynamic data and logs that cannot be defined ahead of time. For these, establish a replication strategy - stream or copy data to a backup so it can be restored when infrastructure is rebuilt.
A system that cannot be rebuilt is a system that cannot be trusted.
3. Create Disposable Things
Section titled “3. Create Disposable Things”Design components so they can be added, removed, started, stopped, changed, and moved without ceremony. Treat servers like cattle, not pets - identical resources automatically replaced when broken, not hand-maintained individuals with names and unique configurations.
When components are constantly appearing and disappearing, surrounding tools must cope: monitoring systems should expect routine replacement without triggering false alarms, while still alerting on real problems like infinite rebuild loops.
4. Avoid Snowflake Systems
Section titled “4. Avoid Snowflake Systems”A snowflake is an instance so difficult to rebuild that the team fears touching it - often created by rushed first-time deployments or inconsistent manual fixes applied to only some instances.
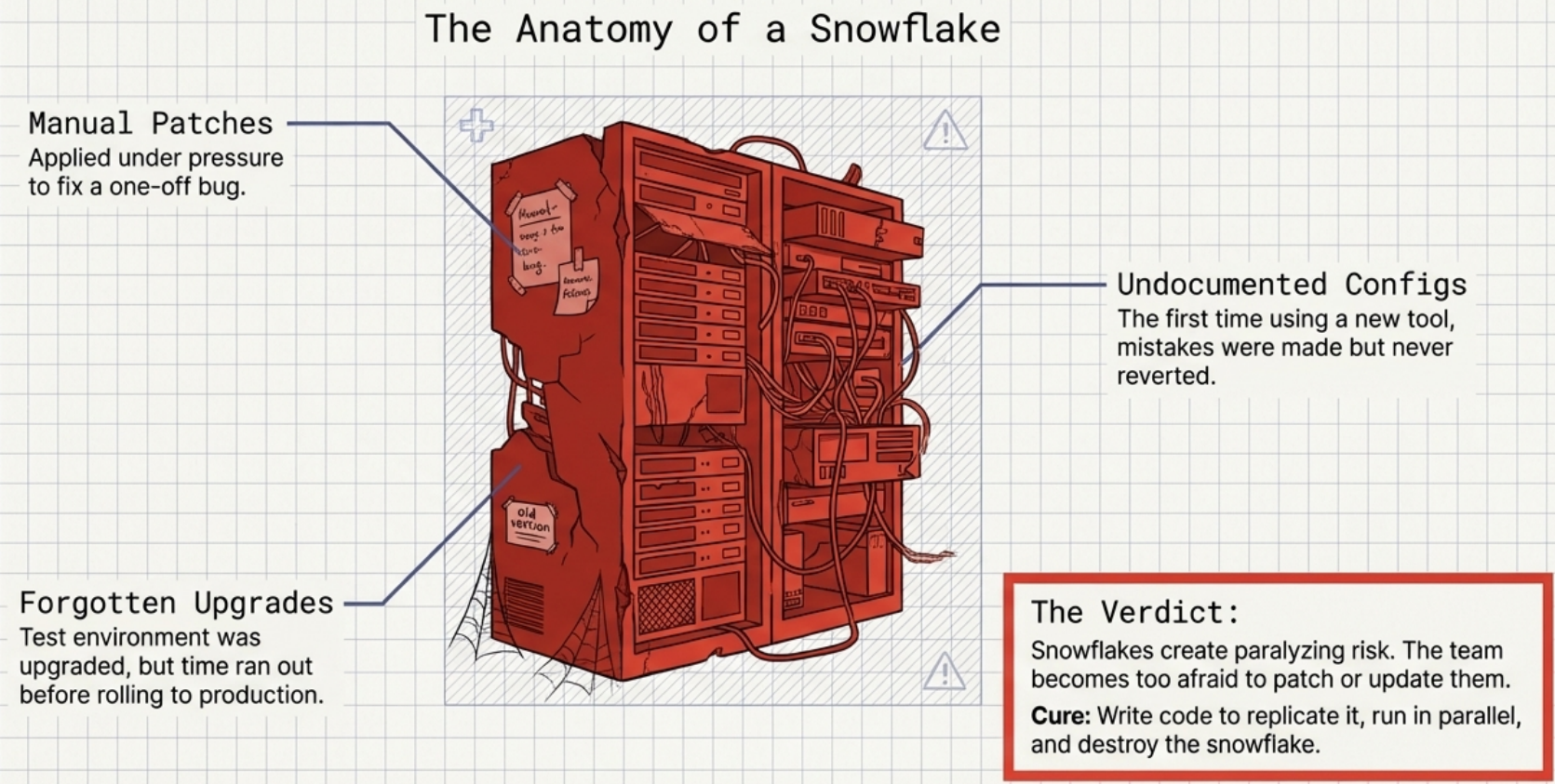
The solution: write fresh infrastructure code to replicate it, run the new system in parallel, validate with automated tests, and retire the original once ready.
5. Minimize Variation
Section titled “5. Minimize Variation”Managing 100 identical servers is far easier than managing 5 different ones. Distinguish necessary variation (a service genuinely needs a specialised database) from unintended variation (two similar services using different databases without reason).
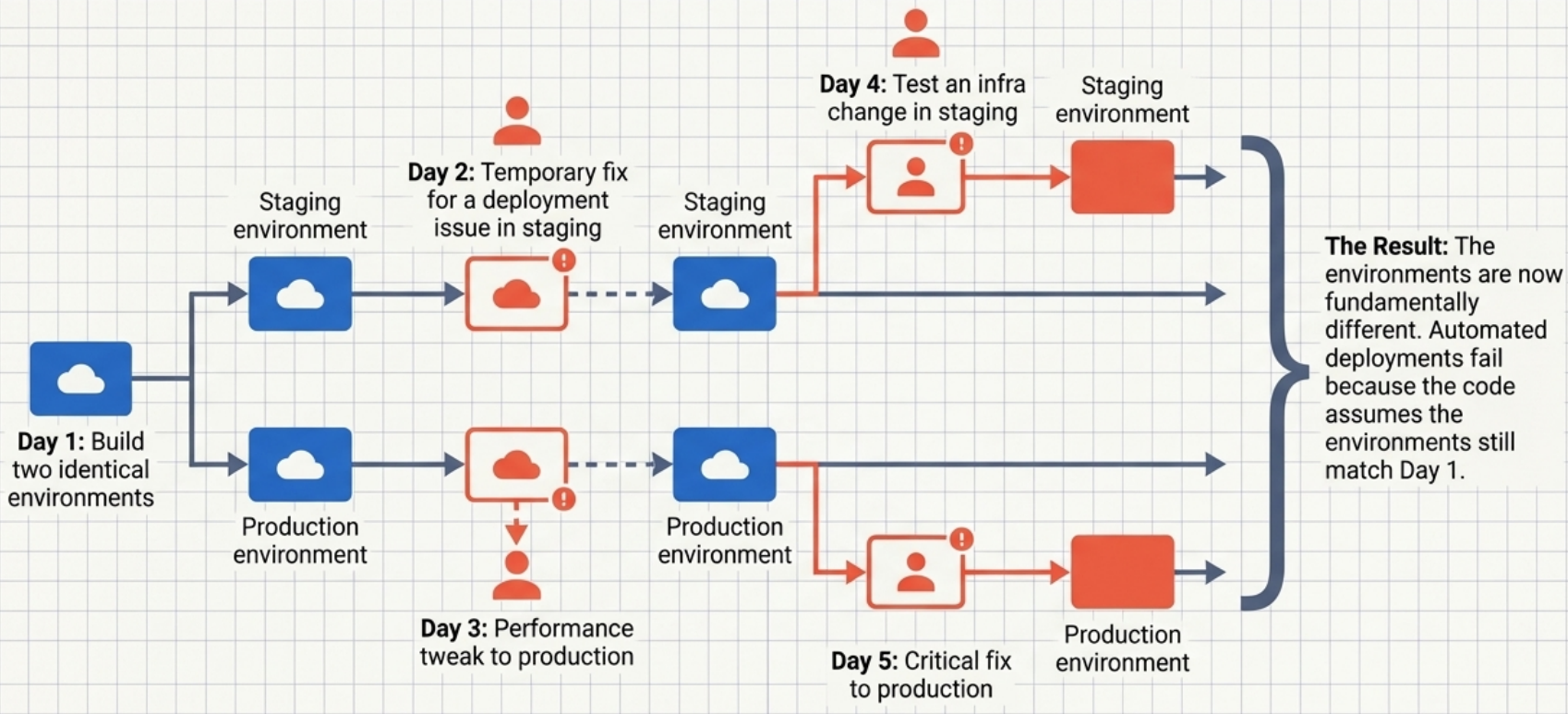
Configuration drift - the most common form of unintended variation - happens when environments meant to be identical gradually diverge through manual fixes, ad hoc automation runs, or separate copies of infrastructure code. This directly feeds the Automation Fear Spiral below.
6. Ensure Any Procedure Can Be Repeated
Section titled “6. Ensure Any Procedure Can Be Repeated”Runbooks become pipelines. No operational step should require human decision-making that could produce different results each time. If a procedure cannot be repeated identically by running code, it is not IaC - it is documentation with extra steps.
7. Apply Software Design Principles
Section titled “7. Apply Software Design Principles”Separation of concerns, single responsibility, DRY, loose coupling - these all apply to infrastructure code. The transfer is not one-to-one (there are tricky differences between application code and infrastructure code), but the fundamental design concepts are highly relevant and directly improve maintainability.
The Three Myths of Infrastructure Change
Section titled “The Three Myths of Infrastructure Change”When organizations attempt to adopt IaC, they encounter resistance rooted in three pervasive misunderstandings:
Myth 1: Infrastructure doesn’t change very often. Few systems stop changing before they are retired. Infrastructure continuously requires new features, software upgrades, security patches, architectural scaling, and configuration changes. Teams relying on heavyweight change-request processes accumulate a backlog of outdated, unpatched, and vulnerable systems - not because change is inherently risky, but because they made change expensive.
Myth 2: We can build infrastructure first and automate it later. Automation must be integral to the system’s design from the start - retrofitting it is highly impractical and almost never happens in practice. Building manually first sacrifices automated testing, fast rebuilds, and rapid delivery during the most critical phase: initial build. If the manual system is successful, stakeholders will always prioritize new features over going back to add automation. The correct approach: build incrementally, automating as you go, starting with the bare minimum needed to deliver the first business increment.
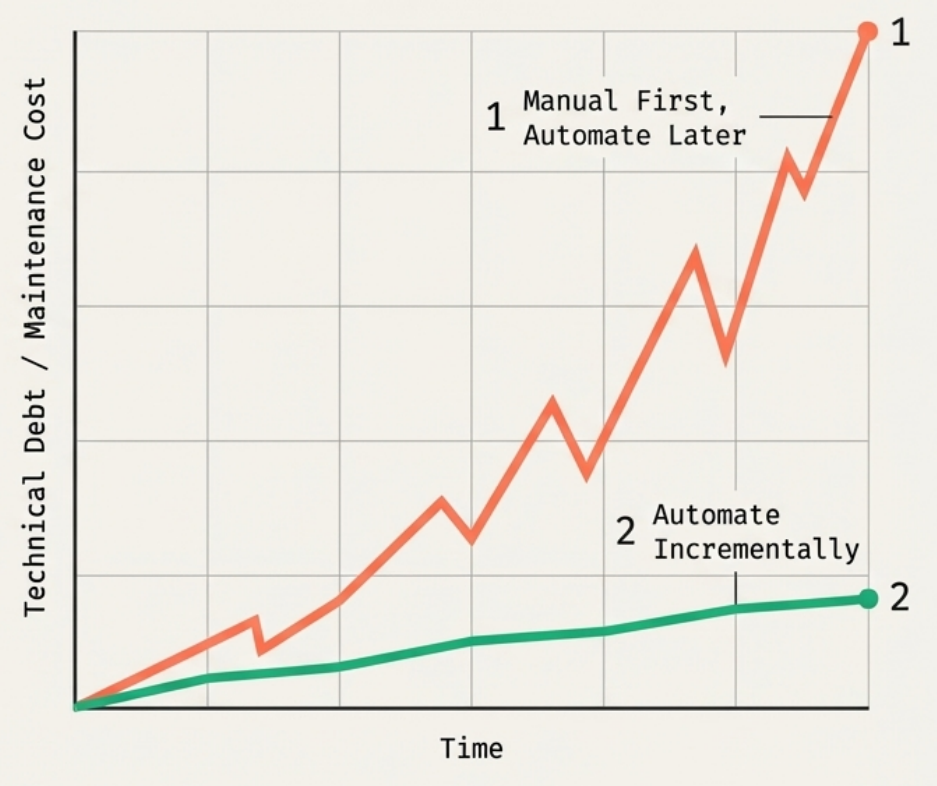
Myth 3: Speed and quality are trade-offs. Research (Accelerate) consistently shows that high-performing organizations achieve both high speed and high quality simultaneously - these reinforce each other rather than opposing. Speed and quality form a quadrant, not a continuum:

| High quality | Low quality | |
|---|---|---|
| High speed | ✅ High performers (DevOps target) | 💥 The Fragile Mess - fast until the debt catches up |
| Low speed | 🪤 The Heavyweight Trap - governance that blocks improvement | ❌ Worst of both worlds |
Teams trying to choose one dimension over the other reliably end up doing poorly at both.
The Automation Fear Spiral
Section titled “The Automation Fear Spiral”Configuration drift - where identical environments gradually diverge through manual fixes - creates a toxic cycle that paralyses automation adoption:
- A manual change is made under time pressure (a quick fix, a performance tweak, an emergency patch)
- Infrastructure becomes inconsistent - servers that should be identical are now different
- Fear sets in - the team loses confidence that running automated code across all instances will break the manually-tweaked ones
- Automation is avoided - more manual changes are made instead, deepening the inconsistency
- Repeat - the spiral tightens until the team abandons automation entirely
You can identify a team caught in the spiral by one symptom: they have automation tools (Ansible, Terraform, Puppet) but are afraid to run them.
Breaking the spiral requires building confidence incrementally:
- Pick one single set of servers or resources
- Verify the infrastructure code can be applied and reapplied to those resources cleanly
- Schedule a continual automated run (hourly or on commit) against that set
- Expand to the next set only once the first is stable
- Use monitoring and automated tests to catch new drift immediately, before the fear can rebuild
Aligning Infrastructure with Organizational Strategy
Section titled “Aligning Infrastructure with Organizational Strategy”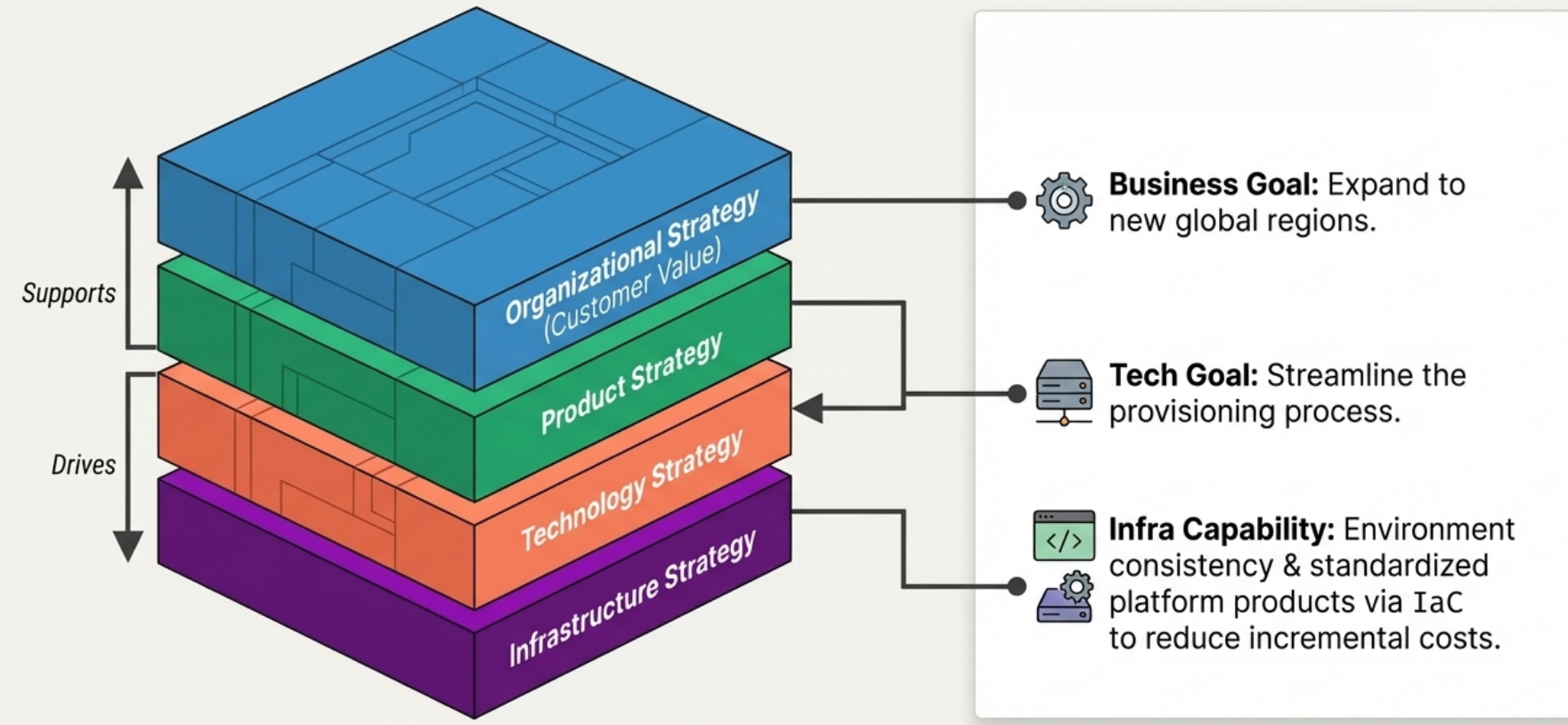
The Strategic Hierarchy The alignment of infrastructure with an organization’s broader goals is fundamentally driven by customer value. This creates a top-down strategic flow where organizational strategy drives product strategy, which drives technology strategy, and ultimately dictates infrastructure strategy. In return, each foundational technical layer must be designed to explicitly support the strategic business layers above it.
The Disconnect Between Leadership and Engineering A significant challenge for many organizations is the communication gap between the people making strategic commercial decisions and the engineers building the foundational systems.
- Leadership blind spots: Organizational leaders often dismiss the need for detailed infrastructure planning, mistakenly assuming that simply selecting a cloud vendor is the end of the process. When architectural problems eventually limit growth, security, or stability, these leaders tend to demand quick fixes rather than addressing the structural root causes.
- Engineering blind spots: Conversely, engineering teams frequently focus on implementing obvious technical solutions without thoroughly understanding the commercial context or the end-user requirements. For example, an engineering team once built a highly segregated multiregion cloud architecture to strictly comply with privacy regulations. Because they did not communicate closely with the commercial strategy team, they missed a critical business requirement: users needed international roaming access while traveling abroad. This strategic misalignment resulted in massive delays, immense expense, and a necessary total rework of the system architecture.
Mapping Business Goals to Infrastructure Capabilities To prevent costly misalignments, it is essential that everyone—from boardroom executives to software developers—understands how technical architecture either enables or hinders strategic success. Specific business goals directly require specific infrastructure capabilities:
- Delivering continuous customer value: To release new products and features quickly and reliably, an organization requires infrastructure that easily supports developing, testing, and hosting services. Success in this area is measured by strong performance on the four key metrics (delivery lead time, deployment frequency, change fail percentage, and MTTR) and a low dependency on platform teams for routine software delivery tasks.
- Growing revenue and expanding into new markets: Expanding into new geographic regions or launching new product lines demands the ability to rapidly deploy new hosting environments and system capacity. The effectiveness of this infrastructure is measured by the speed at which new hosting can be added and the incremental cost of each new region or product instance.
- Providing highly reliable services: To maintain customer trust and satisfaction, systems must possess robust scaling, disaster recovery, and monitoring capabilities. Success here is tracked through standard availability and performance metrics.
The Role of Infrastructure as Code in Achieving Strategic Alignment Broad organizational objectives ultimately filter down into specific, actionable goals for infrastructure architecture. Key strategic infrastructure requirements usually include environment consistency, self-service provisioning, automated recovery testing, and standardized platform products.
Adopting Infrastructure as Code (IaC) is highly effective for achieving these critical goals. For instance, IaC enforces environment consistency across the entire development lifecycle, ensuring that test environments perfectly mirror live production environments. This one foundational infrastructure capability ripples upward to support multiple high-level business goals by:
- Improving software delivery effectiveness and speed.
- Minimizing the manual customization and effort required when expanding into new global regions or launching new products.
- Making it significantly easier to automate overarching operational necessities like system security, regulatory compliance, and disaster recovery.
- Allowing the organization to consolidate, simplify, and rationalize its overall system architecture.
IaC and CI/CD
Section titled “IaC and CI/CD”IaC and CI/CD are the same discipline applied to different artifacts. The pipeline that runs terraform apply is constructed the same way as the pipeline that deploys application code - it validates, tests, stages, and promotes. The difference is the artifact at the center:
| Software CI/CD | Infrastructure CI/CD |
|---|---|
| Build artifact from source | Generate plan from Terraform config |
| Run unit + integration tests | Run terraform validate, tflint, Checkov |
| Deploy to staging | Apply to a test environment |
| Deploy to production | Apply to production |
| Monitor and roll back | Detect drift, run terraform apply to reconcile |
Infrastructure “artifacts” (a GKE cluster, a Cloud SQL instance) take minutes to provision and are expensive to test in isolation. This shapes the testing strategy significantly - covered in Testing IaC and the delivery pipeline in IaC & CI/CD.